

Google has just announced the development of a new AI tool that is going to blow your mind it’s called Lumiere.
it’s an AI video model that can generate realistic diverse and coherent videos from Simple Text prompts
Lumiere is an advanced AI video model
So Lumiere is an advanced AI video model that was developed by a team of researchers at Google it was introduced in a paper that was published on the archive pre-print server on January 24th 2024
Text To Video
Lumiere is a text-to-video diffusion model which means that it uses a technique called diffusion to generate videos from text Diffusion is a process that starts with a noisy image and gradually refines it until it matches the desired output

Features
Lumiere uses diffusion to create videos that portray realistic diverse and coherent motion which is a pivotal challenge in video synthesis it is based on a novel architecture called SpaceTime unet.
SpaceTime Unet
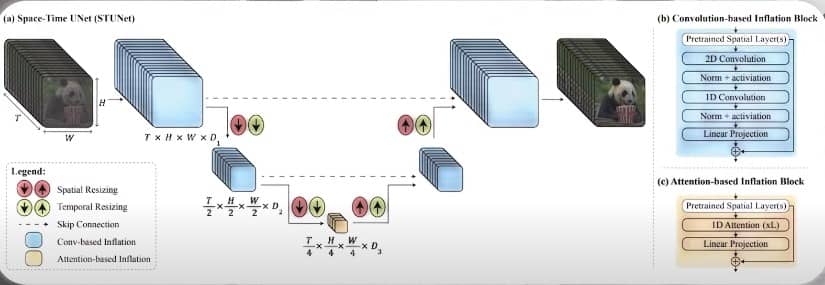
which generates the entire temporal duration of the video at once through a single pass in the model this is different from existing video models which synthesize distant key frames followed by temporal super-resolution which can result in inconsistent and unrealistic motion by using both spatial
and temporal down and upsampling Lumiere can process video Creation in multiple space-time scales and generate full frame rate low-resolution videos Lumiere is also multimodal.
Videos From Text Image Both

So it can generate videos from text from images or from a combination of both it can also generate videos in different styles using a single reference image or a text prompt interestingly it can even animate specific regions of an image
or in paint missing parts of a video the model uses the space-time unet architecture to generate videos from text in a diffusion-based manner it first encodes the text prompt into a latent Vector using a pre-trained text-to-image diffusion model.
It then uses the latent Vector to condition the diffusion process which consists of several steps in each step Lumiere applies the SpaceTime unet to the noisy video and produces a slightly less noisy video.
it repeats this process until the final video is generated which matches the text prompt Now it can also generate videos from images or from a combination of images and text by using a similar
diffusion-based process first it encodes the image or the image text pair into a latent Vector using a pre-trained textto image diffusion model then uses the latent Vector to condition the diffusion process which consists of several steps in each step
the model applies the SpaceTime unet to the noisy video and produces a slightly less noisy video and again it repeats this process until the final video is generated which matches the image or the image text pair
Text-To-Video Synthesis
Lumiere is an advanced AI video model that’s really versatile and Powerful it has a bunch of features that are pretty cool for instance with text-to-video synthesis you can just type in anything like “a dog chasing a ball in the park”

and the model will create a video out of your description then there’s image to video conversion say you have a picture of a flower Lumiere can make a video
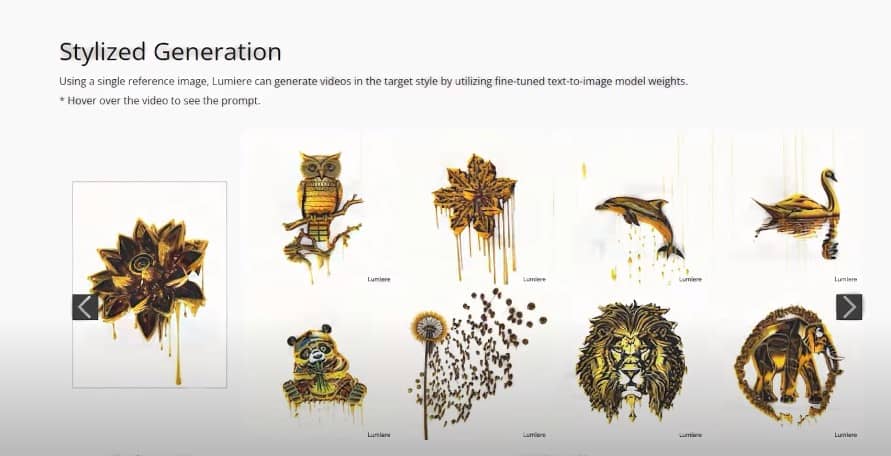
where flowers are blooming in Antarctica, it’s like taking a still image and giving it life with the stylized generation it takes an image you upload and uses its style to create videos For example upload a sticker and it makes videos
that looks like that sticker style animating specific regions is another feature you can upload any image choose a part of it you want to move and
Lumiere makes a video where just that part is animated like if you have a picture of a lake you can make just the water move video in Painting is about editing parts of a video upload a video choose a part you want to change and

Lumiere does the rest like if you have a video of a girl dancing you can change just her dress now comparing Lumiere to other AI video models like Runway and pabs Lumiere actually stands out it uses
this unique SpaceTime unet architecture which lets it make a whole video in one go, this is more efficient than other models that need several steps Lumiere also uses a technique where it starts with a rough image and gradually makes
Its better until it’s just right this is different from other models that might have issues like blurriness or weird glitches lastly the model is user-friendly and creative it can make videos from text images or both and in various Styles you can animate parts of an image or fix parts of a video.

and you can do all this with just a few clicks or words this makes Lumiere easier and more fun to use than other models that might need more work from the user basically Lumiere could be a big help in any situation where you need to make a video making the process easier quicker
Big Deal For Google’s Stuff
More enjoyable it could also be a big deal for Google’s own stuff like

YouTube Google photos and Google Assistant Imagine being able to make and upload videos on YouTube Just from text or pictures or tweaking your current videos or with Google photos turning your pictures into videos adding animations and fixing parts of your photos and with Google Assistant you could just ask for a video
using your voice or have more fun interactions with videos but there are some challenges and concerns with Lumiere especially about ethics and creativity one big worry is about how real the videos look Lumiere can make videos that are super realistic
but it can also make fake ones that could trick people these fake videos called Deep fakes could be used in bad ways like spreading lies ruining reputations or swaying people’s opinions
this is a real risk to how much we can trust what we see and hear another concern is about who owns the videos and if they’re original Lumiere makes making videos really easy but this could mean less challenge and satisfaction in the creative process.
It could also mean relying Less on human skills and creativity which might make videos feel less special all right that wraps up our video about Lumiere